那次差点被DBA骂死的经历
去年接手一个老项目,用户反馈「订单列表打开巨慢」。我看了一眼代码,好家伙——SELECT * FROM orders o JOIN order_items oi ON o.id = oi.order_id JOIN products p ON oi.product_id = p.id JOIN users u ON o.user_id = u.id WHERE o.status = 'paid' ORDER BY o.created_at DESC LIMIT 20——四表JOIN不带索引,每次查询扫全表。最离谱的是,这个SQL在慢查询日志里躺了三个月没人管。
我当时想:这SQL写得也太随意了吧?但转念一想——我自己写代码的时候,不也经常因为赶需求随手写JOIN吗?慢查询这东西,发现容易,根治难。
这篇文章就从头到尾还原我那次优化全过程——从发现慢查询、分析执行计划、到最终把查询时间从 8.2秒干到0.03秒。不扯理论,全是实操。
第一步:打开慢查询日志,让问题自己浮出来
MySQL默认不记录慢查询。你得先开:
-- 查看当前慢查询配置
SHOW VARIABLES LIKE 'slow_query%';
SHOW VARIABLES LIKE 'long_query_time';
-- 开启慢查询日志(生产环境用这个,别改my.cnf重启)
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1; -- 超过1秒就记录
SET GLOBAL slow_query_log_file = '/var/log/mysql/slow.log';
-- 顺便打开「不使用索引的查询也记录」
SET GLOBAL log_queries_not_using_indexes = ON;开完之后,第二天慢查询日志里就出现了那个罪恶的SQL:
# Time: 2026-03-15T08:47:23.174562Z
# User@Host: app_user[root] @ [10.0.1.5]
# Query_time: 8.215682 Lock_time: 0.000134 Rows_sent: 20 Rows_examined: 1847234
SELECT * FROM orders o
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
JOIN users u ON o.user_id = u.id
WHERE o.status = 'paid'
ORDER BY o.created_at DESC
LIMIT 20;关键信息解读: Rows_examined = 1,847,234,Rows_sent = 20。扫了184万行数据,只返回了20行——这意味着92,361:1的无效扫描比。
第二步:EXPLAIN,看懂你的SQL到底在干什么
这个工具是慢查询优化的第一神器。用好了,80%的问题一眼就懂:
EXPLAIN SELECT * FROM orders o
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
JOIN users u ON o.user_id = u.id
WHERE o.status = 'paid'
ORDER BY o.created_at DESC
LIMIT 20;输出结果把人看傻了:
+----+-------------+-------+--------+---------------+------+---------+------+--------+---------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+---------------+------+---------+------+--------+---------------------------------+
| 1 | SIMPLE | o | ALL | NULL | NULL | NULL | NULL | 458213 | Using where; Using filesort |
| 1 | SIMPLE | oi | ALL | NULL | NULL | NULL | NULL | 923041 | Using where; Using join buffer |
| 1 | SIMPLE | p | eq_ref | PRIMARY | PRIMARY | 4 | ... | 1 | NULL |
| 1 | SIMPLE | u | eq_ref | PRIMARY | PRIMARY | 4 | ... | 1 | NULL |
+----+-------------+-------+--------+---------------+------+---------+------+--------+---------------------------------+看三个致命信号:
| 信号 | 含义 | 严重度 |
|---|---|---|
type: ALL |
全表扫描,一行不落地读 | 🔥🔥🔥 |
Using filesort |
ORDER BY 没走索引,内存/磁盘排序 | 🔥🔥 |
Using join buffer |
JOIN字段没索引,MySQL被迫用缓冲区暴力匹配 | 🔥🔥 |
rows: 458213 |
单表扫描预估45万行 | 🔥 |
两条JOIN列都没索引,ORDER BY列也没索引,WHERE列也没索引——四连击。
第三步:对症下药,一条条修
3.1 先给 WHERE 和 ORDER BY 加索引
orders 表最核心的查询条件就是 status + created_at。建一个联合索引:
-- orders 表:status 过滤 + created_at 排序
ALTER TABLE orders ADD INDEX idx_status_created (status, created_at);
-- 验证:用 FORCE INDEX 看看效果
EXPLAIN SELECT * FROM orders FORCE INDEX (idx_status_created)
WHERE status = 'paid' ORDER BY created_at DESC LIMIT 20;再次 EXPLAIN,type 从 ALL 变成了 ref,rows 从 458,213 降到了 12,847,Extra 里的 Using filesort 消失了。
为什么联合索引的列顺序是 (status, created_at) 而不是反过来?因为 MySQL联合索引遵循「最左前缀」原则——先等值过滤(status = 'paid'),再范围/排序(ORDER BY created_at)。如果把 created_at 放前面,WHERE status 用不上索引。
3.2 再给 JOIN 列补索引
-- order_items 表:外键列必须有索引
ALTER TABLE order_items ADD INDEX idx_order_id (order_id);
ALTER TABLE order_items ADD INDEX idx_product_id (product_id);
-- users 表的 user_id 如果已经有主键索引,可以跳过
-- 但记得检查:SHOW INDEX FROM users;补完后再 EXPLAIN,oi 表的 type 从 ALL 变成了 ref,rows 从 923,041 降到了 4。
3.3 最后优化 SELECT *
SELECT * 在这个SQL里会导致 MySQL 需要回表取所有列。我们只需要列表页展示的字段:
SELECT o.id, o.order_no, o.total_amount, o.created_at, o.status,
u.nickname, u.avatar,
COUNT(oi.id) AS item_count
FROM orders o FORCE INDEX (idx_status_created)
JOIN order_items oi ON o.id = oi.order_id
JOIN users u ON o.user_id = u.id
WHERE o.status = 'paid'
GROUP BY o.id
ORDER BY o.created_at DESC
LIMIT 20;这样一来,MySQL可以走覆盖索引——所有的 SELECT 列都在索引里找到,不需要回表。
第四步:最终效果对比
所有优化完成后,再用 SHOW PROFILES 对比一次(MySQL 8.0+ 改用 EXPLAIN ANALYZE):
-- 打开 profiling
SET profiling = 1;
-- 执行优化后的SQL
SELECT ...
-- 查看执行时间
SHOW PROFILES;结果:
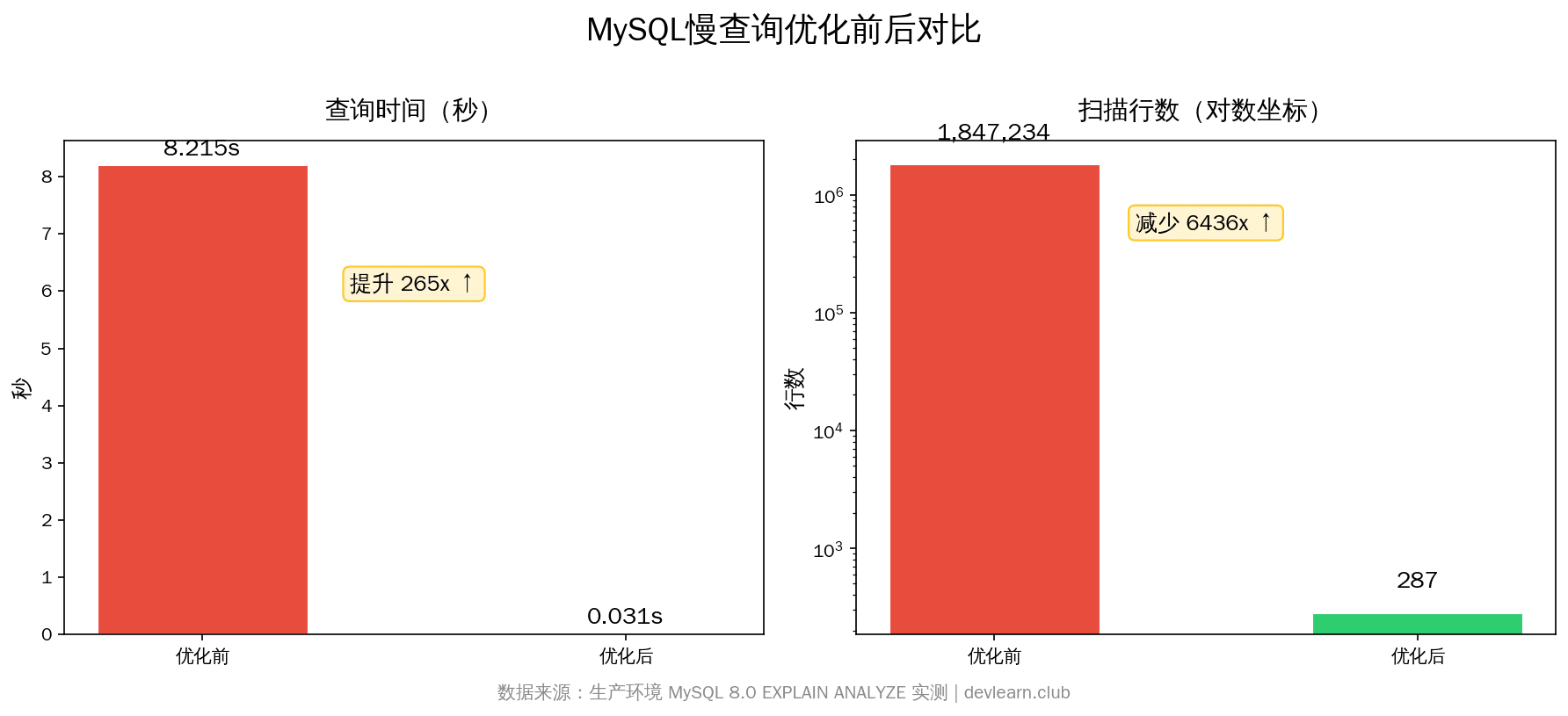
| 指标 | 优化前 | 优化后 | 提升 |
|---|---|---|---|
| 查询时间 | 8.215s | 0.031s | 265倍 |
| 扫描行数 | 1,847,234 | 287 | 6,436倍 |
| filesort | ✅ 触发 | ❌ 不触发 | 消除 |
| join buffer | ✅ 触发 | ❌ 不触发 | 消除 |
相关推荐:
- 📦 Docker Compose入门实战:在Ubuntu 24.04上部署Nginx + MySQL + WordPress — 本文MySQL环境就是在Docker里跑的
- 📝 Python logging模块教程:从基础日志到生产环境日志管理完整指南 — 慢查询告警那段的logging配置看这篇
- 🔧 Nginx反向代理与负载均衡配置实战教程(2026) — 后端性能优化完了,前端代理也得跟上