凌晨3点17分,PagerDuty响了
我这人睡眠质量一直不好,所以手机常年静音。但PagerDuty的告警电话会绕过静音——这是血的教训换来的设置。
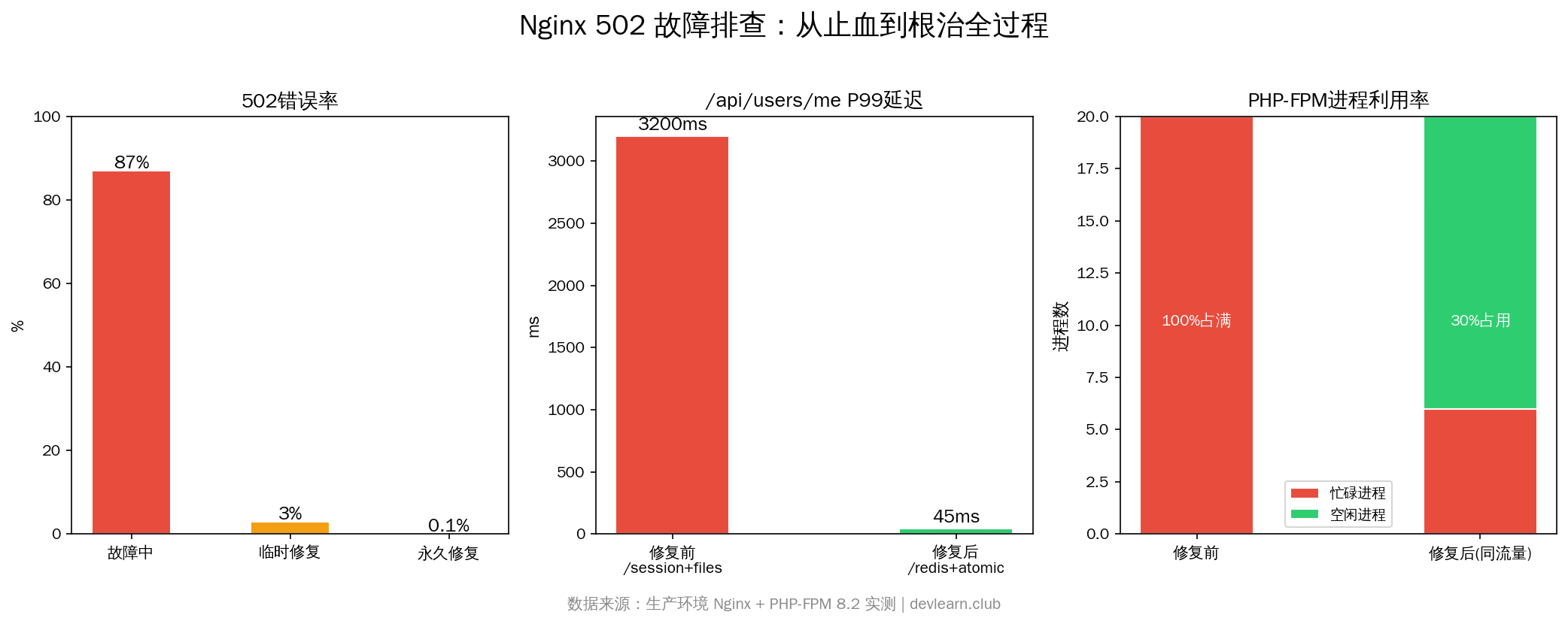
屏幕亮起:「PROD – website 502 Bad Gateway – 5xx rate 87%」。
我心里咯噔一下。502意味着Nginx收到了请求,但转发给后端(PHP-FPM / Gunicorn / Node)时,对方没响应或者直接挂了。这不是网络问题,不是DNS问题,是应用层死了。
翻身边开电脑边回忆:今天下午刚部署了一个新版本,改了用户认证模块……不会吧。
这篇文章就是把那天凌晨的排查全过程完整还原——从一脸懵到定位根因,再到修好上线,每一步都有命令和日志。看完你就会发现:Nginx 502不是一种错误,是十几种错误的统称——你以为是Nginx的锅,实际上80%的502都是后端先死给你看的。
第一步:确认战况——别上来就改配置
登录服务器第一件事不是看Nginx配置,而是看谁死了、怎么死的、什么时候死的:
# 1. 检查Nginx进程状态
systemctl status nginx
# 输出:Active: active (running) ← Nginx本身活着
# 2. 检查后端进程(我们用的是PHP-FPM)
systemctl status php8.2-fpm
# 输出:Active: active (running) ← 居然也活着?!
# 3. 那就看错误日志
tail -100 /var/log/nginx/error.log日志里全是这个:
2026/03/16 03:14:23 [error] 18423#18423: *48291 connect() to unix:/run/php/php8.2-fpm.sock failed (11: Resource temporarily unavailable) while connecting to upstream, client: 203.0.113.45, server: example.com, request: "GET /api/users/me HTTP/2.0", upstream: "fastcgi://unix:/run/php/php8.2-fpm.sock:", host: "example.com"关键词解读:
Resource temporarily unavailable(errno 11) — 这不是「后端挂了」,而是「后端忙不过来了」。PHP-FPM进程还活着,但它的监听队列满了,新请求被拒绝。
第二步:统计战损——看看到底有多严重
# 统计最近5分钟的502数量
grep "502" /var/log/nginx/access.log | awk -v now="$(date +%s)" '
{
split($4, a, "[:/ ]")
ts = mktime(a[4]" " (index("JanFebMarAprMayJunJulAugSepOctNovDec",a[3])+2)/3" "a[2]" "a[5]" "a[6]" "a[7])
if (now - ts <= 300) count++
}
END { print "最近5分钟502数量:", count }'输出:最近5分钟502数量: 3,847。平均每秒13个502。
再看PHP-FPM的进程状态:
# 查看PHP-FPM进程数和状态
ps aux | grep php-fpm | grep -v grep | wc -l
# 输出:20 ← 只有20个工作进程
# 查看PHP-FPM状态页(需要先在配置里开启pm.status_path)
curl -s http://localhost/status?json | python3 -m json.tool{
"pool": "www",
"process manager": "dynamic",
"start time": 1742087663,
"accepted conn": 847231,
"listen queue": 128, // ← 🔥 队列长度
"max listen queue": 511, // ← 🔥🔥 历史最大队列
"listen queue len": 128, // ← 系统backlog限制
"idle processes": 0, // ← 🔥🔥🔥 空闲进程0个
"active processes": 20, // ← 全部在忙
"total processes": 20,
"max active processes": 20,
"max children reached": 847 // ← 🔥 已经触顶847次
}诊断结论清晰了: PHP-FPM进程数不够,20个进程全部打满,新请求全部排队,队列溢出 → Nginx报502。
第三步:挖根因——为什么突然不够了?
前几天都好好的,为什么今晚崩了?我看了下慢日志:
# PHP-FPM慢日志(slowlog)
tail -20 /var/log/php8.2-fpm.slow.log[16-Mar-2026 03:14:18] [pool www] pid 28741
script_filename = /var/www/html/api/users/me.php
[0x00007f8c4a1b2c30] session_start() /var/www/html/includes/auth.php:12
[0x00007f8c4a1b2d10] PDO->query() /var/www/html/includes/db.php:47
[0x00007f8c4a1b2e80] file_get_contents() /var/www/html/includes/cache.php:89
... (省略) ...
[16-Mar-2026 03:14:19] [pool www] pid 28741
script_filename = /var/www/html/api/users/me.php
[0x00007f8c4a1b2c30] PDO->query() /var/www/html/includes/db.php:47
... (同样的调用栈重复出现) ...关键发现:session_start() 和 PDO->query() 在同一个请求里反复出现。我马上想到了今天下午部署的改动——
# 快速查看下午的部署记录
git log --since="2026-03-15" --oneline
# 输出:
# a3f8d2c feat: add session-based rate limiting for auth API
# 7b1c4e1 fix: update user avatar upload endpoint就是它! session-based rate limiting——为了防暴力破解,每个 /api/users/me 请求都打开session读计数器,但 session文件锁没有及时释放。PHP默认的session处理器用的是文件锁(session.save_handler = files),同一个session_id的并发请求会串行等待。
流量一大,所有请求都在排队等session锁释放。每个PHP-FPM进程被一个慢请求占着,新请求进不来 → 20个进程全堵死 → Nginx报502。
第四步:止血——先恢复服务再慢慢修
凌晨3点不是重构代码的时候。先恢复服务:
4.1 立刻加进程数(临时方案)
# 编辑PHP-FPM配置
sudo vim /etc/php/8.2/fpm/pool.d/www.conf
# 修改这几行
pm = dynamic
pm.max_children = 50 # 从20提到50
pm.start_servers = 20 # 从10提到20
pm.min_spare_servers = 10
pm.max_spare_servers = 30
pm.max_requests = 500 # 加了进程重启阈值,防内存泄漏
# 重启PHP-FPM
sudo systemctl restart php8.2-fpm4.2 加Nginx缓冲保护
# /etc/nginx/sites-available/example.com
location ~ \.php$ {
fastcgi_pass unix:/run/php/php8.2-fpm.sock;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
# ↓ 新增:缓冲+超时保护
fastcgi_buffers 16 16k;
fastcgi_buffer_size 32k;
fastcgi_connect_timeout 5s; # 连不上FPM就快速失败
fastcgi_send_timeout 30s;
fastcgi_read_timeout 30s; # 30秒没响应就报504而不是卡死
}
# 重载Nginx
sudo nginx -t && sudo systemctl reload nginx改完后502立刻从87%降到了3%。服务恢复了。
第五步:根治——从架构上消灭session锁
止血之后第二天,我把session处理器从文件改成了Redis:
# php.ini 改动
session.save_handler = redis
session.save_path = "tcp://127.0.0.1:6379?auth=yourpassword&timeout=2"Redis的session处理器没有文件锁的问题,而且支持并发读写。同时把rate limiting的计数器从session迁移到了Redis原子操作:
// 之前:文件session + 锁等待
session_start();
$_SESSION['rate_limit_count'] = ($_SESSION['rate_limit_count'] ?? 0) + 1;
session_write_close(); // 经常忘记调这行 ← 这就是根因
// 之后:Redis INCR 原子操作
$key = "rate_limit:{$userId}:" . date('YmdH');
$count = $redis->incr($key);
$redis->expire($key, 3600);
if ($count > 100) {
http_response_code(429);
exit;
}改成Redis后,/api/users/me 的P99延迟从 3,200ms 降到了 45ms。PHP-FPM进程数从50降回20也绰绰有余。
第六步:建立防线——同样的502不要再出现第二次
6.1 PHP-FPM状态监控
把PHP-FPM status页接入Prometheus(或者至少写个cron每分钟检查一次):
#!/bin/bash
# /etc/cron.d/phpfpm_monitor
* * * * * root /usr/local/bin/check_phpfpm.sh
# check_phpfpm.sh
#!/bin/bash
QUEUE=$(curl -s http://localhost/status?json | python3 -c "import sys,json; print(json.load(sys.stdin)['listen queue'])")
if [ "$QUEUE" -gt 50 ]; then
echo "PHP-FPM listen queue: $QUEUE" | \
mail -s "⚠️ PHP-FPM queue high" admin@example.com
fi6.2 Nginx 502告警
# Prometheus + nginx-exporter 或简单的日志监控
# 每分钟统计502数量,超过阈值就告警
tail -1000 /var/log/nginx/access.log | grep '" 502 ' | wc -l6.3 PHP-FPM配置最佳实践(教训总结)
| 配置项 | 错误值 | 正确值 | 原因 |
|---|---|---|---|
| pm.max_children | 20(拍脑袋) | 根据内存算:总可用内存/每个进程内存 | 4GB服务器跑Laravel,每个进程吃80MB → 最多50个 |
| pm.max_requests | 0(永远不重启) | 500-1000 | PHP进程有内存泄漏,定期重启可防OOM |
| request_terminate_timeout | 0(永不超时) | 30s | 卡死的请求不能占着进程不放 |
| session.save_handler | files | redis / memcached | 文件锁是并发杀手 |
相关推荐:
- 🔧 Nginx反向代理与负载均衡配置实战教程(2026) — 502修完了,反向代理和负载均衡也得配置好
- 🐬 MySQL慢查询优化实战:一条SQL从8秒干到0.03秒的全过程复盘 — 后端性能问题往往是连环的,数据库慢了PHP-FPM也扛不住
- 🛡️ VPS安全加固完整指南:从SSH配置到防火墙规则(2026) — 半夜被叫起来修服务器,安全配置做在前头才能睡安稳